
从FM和FFM说起的各种深度CTR预估模型(上)
背景
点击率(click-through rate, CTR)是互联网公司进行流量分配的核心依据之一。无论使用什么类型的模型,点利率这个命题可以被归纳到二元分类的问题,我们通过单个个体的特征,计算出对于某个内容,是否点击了,点击了就是1,没点击就是0。对于任何二元分类的问题,最后我们都可以归结到逻辑回归上面。CTR预估技术从传统的Logistic回归,到近两年大火的深度学习,新的算法层出不穷:DeepFM, NFM, DIN, AFM, DCN等。其实这些算法都是特征工程方面的模型,无论最后怎么计算,最后一层都是一个二元分类的函数(sigmod为主)。
早期的人工特征工程 + LR(Logistic Regression):这个方式需要大量的人工处理,不仅需要对业务和行业有所了解,对于算法的经验要求也十分的高。
GBDT(Gradient Boosting Decision Tree) + LR:提升树短时这方面的第二个里程碑,虽然也需要大量的人工处理,但是由于其的可解释性和提升树对于假例的权重提升,使得计算准确度有了很大的提高。
FM-FFM:FM和FFM模型是最近几年提出的模型,并且在近年来表现突出,分别在由Criteo和Avazu举办的CTR预测竞赛中夺得冠军,使得到目前为止,还都是以此为主的主要模型占据主导位置。embeding模型可以理解为FFM的一个变体。
融合模型:对于GBDT和FM,包括FM与神经网络,都是可以进行融合的,通过融合可以大大的提高准确度。
FM起因
FM(Factorization Machine)是由Konstanz大学Steffen Rendle(现任职于Google)于2010年最早提出的,旨在解决稀疏数据下的特征组合问题。
什么叫稀疏数据?
稀疏数据是指在二维表中含有大量空值的数据;即稀疏数据是指,在数据集中绝大多数数值缺失或者为零的数据。
为什么会出现稀疏数据?
对于机器学习领域来说,我们所有的输入的数据都是以数字表示的,为了更好的提取特征,一般例如分类,名称,性别,标签等数据我们都会对其进行One-Hot编码,经过编码之后只有一列是1,其余数据都是0,这就导致了大部分样本数据特征是比较稀疏的。
例如我们的产品有100个分类,那么经过One-Hot编码后就会有100个特征但是这些特征里面只有一个特征为1,也使得这样特征空间剧增,这时候FM就出现了,
因子分解机(Factorization Machines, FM)
FM的论文地址:https://www.csie.ntu.edu.tw/~b97053/paper/Rendle2010FM.pdf
顾名思义,FM通过对于每一维特征的隐变量内积来提取特征组合,论上来讲FM可以对高阶特征组合进行建模,但实际上因为计算复杂度的原因一般都只用到了二阶特征组合。
FM借鉴了矩阵分解的方式,将原来的高维系数矩阵分解成由众多低维矩阵隐向量相乘的结果。
说的通俗一点:在一般的线性模型中,是各个特征独立考虑的,没有考虑到特征与特征之间的相互关系。但实际上,大量的特征之间是有关联的,而FM就是通过将一个大的矩阵分解成2个小矩阵相乘的形式来提取各个特征之间的关联度。
传统的Logistic Regression计算公式如下:
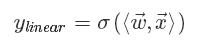
FM模型其实就是对特征两两相乘(组合)构成新特征(离散化之后其实就是“且”操作),并对每个新特征分配独立的权重,通过机器学习来自动得到这些权重。将其写成矩阵形式为:
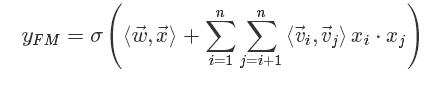
FM模型中特征两两相乘(组合)的权重是相互不独立的,它是一种参数较少但表达力强的模型
基于领域的因子分解机(Field-aware Factorization Machines,FFM)
FFM的论文地址:https://www.csie.ntu.edu.tw/~cjlin/papers/ffm.pdf
FM中间的一个核心步骤就是嵌入,但这个嵌入过程没有考虑领域信息。这使得同领域内的特征也被当做不同领域特征进行两两组合了。
同领域的特征嵌入后直接求和作为一个整体嵌入向量,进而与其他领域的整体嵌入向量进行两两组合。而这个先嵌入后求和的过程,就是一个单领域的小离散特征向量乘以矩阵的过程。
FFM也是FM的另一种变体,也考虑了领域信息。但其不同点是同一个特征与不同领域进行特征组合时,其对应的嵌入向量是不同的
说的简单一点FFM通过引入field的概念,FFM把相同性质的特征归于同一个field,这样使得某些同领域的特征不进行组合。
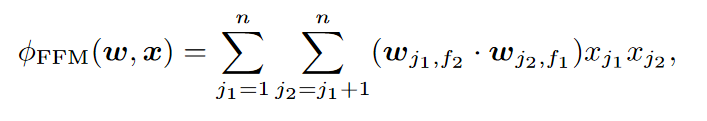
FM可以看作FFM的特例,是把所有特征都归属到一个field时的FFM模型
为了使用FFM方法,所有的特征必须转换成“field_id:feat_id:value”格式,field_id代表特征所属field的编号,feat_id是特征编号,value是特征的值
FM的特点和优势
- 可以在非常稀疏的数据中进行合理的参数估计
- FM模型的时间复杂度是线性的
- FM是一个通用模型,它可以用于任何特征为实值的情况
embedding+MLP:深度学习CTR预估的通用框架
embedding+MLP是对于分领域离散特征进行深度学习CTR预估的通用框架。深度学习在特征组合挖掘(特征学习)方面具有很大的优势。比如以CNN为代表的深度网络主要用于图像、语音等稠密特征上的学习,以W2V、RNN为代表的深度网络主要用于文本的同质化、序列化高维稀疏特征的学习。CTR预估的主要场景是对离散且有具体领域的特征进行学习,所以其深度网络结构也不同于CNN与RNN。 具体来说, embedding+MLP的过程如下:
对不同领域的one-hot特征进行嵌入(embedding),使其降维成低维度稠密特征。然后将这些特征向量拼接(concatenate)成一个隐含层。之后再不断堆叠全连接层,也就是多层感知机(Multilayer Perceptron, MLP,有时也叫作前馈神经网络)。最终输出预测的点击率。
这个模型可以参考fast.ai的Tabular 模块https://docs.fast.ai/tabular.html
参考资料
https://tech.meituan.com/deep_understanding_of_ffm_principles_and_practices.html